Introduction
After successfully installing the Oracle Database 19c software on a three-node Oracle RAC cluster, one of the nodes encountered problems with starting up correctly. The initial analysis of the cluster status using the crsctl check crs command showed that the basic cluster services were online, but there were communication issues with the Cluster Ready Services (CRS), Cluster Synchronization Services (CSS), and the Event Manager (EVM).
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530: Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot communicate with Event Manager
Further analysis of the system logs and the OHASD (Oracle High Availability Services Daemon) logs on the problematic node revealed repeated attempts to start various agents (ORAAGENT, MDNSD, EVMD) and the GPNPD (Grid Plug and Play Daemon) service, with GPNPD shutting down almost immediately after starting.
2025-04-28 10:24:03.791 [ORAAGENT(21773)]CRS-8500: Oracle Clusterware ORAAGENT process is starting with operating system process ID 21773
2025-04-28 10:24:04.083 [GPNPD(21793)]CRS-8500: Oracle Clusterware GPNPD process is starting with operating system process ID 21793
2025-04-28 10:24:04.196 [GPNPD(21793)]CRS-2329: GPNPD on node node01-7 shut down.To identify the cause of the continuous GPNPD restarts, deeper logs specific to this service were analyzed. It turned out that the GPNPD daemon was encountering problems accessing wallet files that were owned by the root user, but should have belonged to the grid user under which the Grid Infrastructure services are run.
2025-04-28 11:05:43.883 : GPNP:3329912064: clsgpnpkwf_initwfloc: [at clsgpnpkwf.c:422] SlfFopen2 failed
Internal Error Information:
Category: SLF_SYSTEM(-8)
Operation: lstat failed
Location: slsfopen3
Other:
Dep: 13
Dep Message: Permission deniedThe log excerpt above clearly indicates a "Permission denied" error when trying to access files in the /u01/app/19.0.0/grid/gpnp/node01-7/wallets/peer/ directory. An analysis of the file ownership in this directory confirmed that they belonged to the root user.
[root@node01-7 peer]# ll
total 4
-rwx------. 1 root oinstall 2949 Apr 25 11:45 cwallet.sso
-rwx------. 1 root oinstall 0 Apr 25 11:45 cwallet.sso.lck
Solution:
To resolve this issue, it was necessary to change the ownership of the cwallet.sso and cwallet.sso.lck files to the correct Grid Infrastructure user and group, which are grid and oinstall. The following commands were executed:
chown grid:oinstall /u01/app/19.0.0/grid/gpnp/node01-7/wallets/peer/cwallet.sso
chown grid:oinstall /u01/app/19.0.0/grid/gpnp/node01-7/wallets/peer/cwallet.sso.lckAfter changing the file ownership, an attempt was made to restart the cluster services. Due to the communication problems, it was necessary to use the -f option to forcefully stop the services:
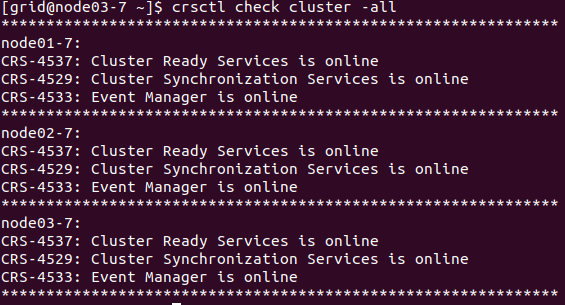
crsctl stop crs -fSubsequently, the node was restarted (reboot). After the reboot, all cluster services on the problematic node started correctly, and the cluster returned to a stable state. The crsctl check crs command confirmed that all components were online and functioning without issues.
Summary:
The described case illustrates potential problems that can occur after installing the Oracle Database 19c software on a RAC cluster, even if the installation process itself proceeded without apparent errors. Incorrect file ownership settings, especially in key configuration directories, can prevent the correct startup of cluster services. Thorough log analysis and verification of file permissions are crucial in diagnosing and resolving such problems. Forcefully stopping the services and restarting the node, after fixing the root cause, allowed for the restoration of the cluster's full functionality.

Comments
No approved comments yet.